groups
People
People must be engaged and accountable throughout the AI lifecycle.
See how enterprises are rethinking their data and AI strategies with Teradata—the Trusted AI company.
People must be engaged and accountable throughout the AI lifecycle.
An open, connected ecosystem creates flexibility and accelerates innovation.
AI and data solutions must scale to unlock cost-effective growth and uncover breakthrough innovations.
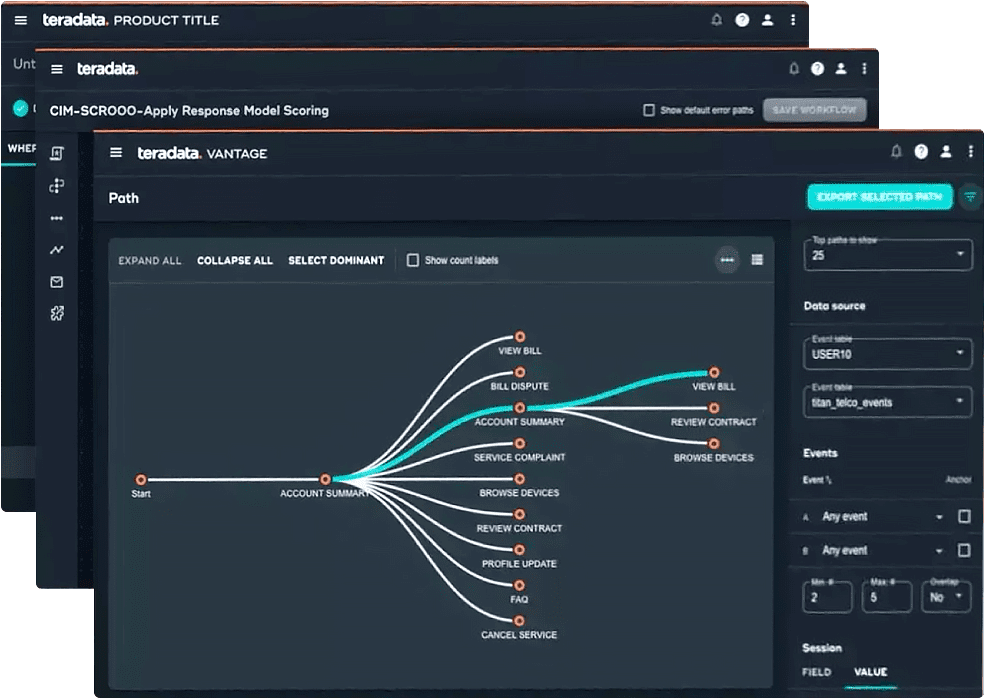
Empower everyone across the organization to innovate faster by easily unifying and harmonizing all your data.
Transform your data into insights that drive breakthroughs again and again with powerful, integrated AI and cloud analytics.
Fuel your most valuable growth opportunities with AI/ML innovation and cost-effective cloud-native technology that scales elastically.






Discover greater possibilities with our network of over 100 partners. Get the unmatched expertise you need to cultivate your best cloud analytics solution.








